LFM2.5-1.2BをOpen WebUI+Ollamaで試す
軽量モデルLFM2.5-1.2BをKubernetes上のOpen WebUI + Ollamaで構築し、JSON出力・情報抽出・制約遵守など各タスクの性能評価とローカルAIの実用性を検証します。
LFMを触るきっかけはGoogle Spread Sheetの大量の値の変換をなんとか上手くできないかと考えていたことでした。当初、Googleスプレッドシートのデータ整形にはGeminiの活用を検討していました。
しかしながら、APIの利用上限やコスト面、さらには特定のタスクへの最適化に課題を感じていました。
そこで、これらの問題を解決するために、最近話題にになっているローカル環境で動作する軽量モデル「LFM2.5-1.2B」に着目し、Open WebUIとOllamaを組み合わせた実証実験を行うことにしました。
そんな中、YouTube等でも「軽量ながら極めて優秀」と話題の LFM2.5-1.2B を、Open WebUIとOllamaを組み合わせて実験してみました。
構成
実行環境
- リソース: 6core CPU / 12GB RAM
- プラットフォーム: 自社運用のKubernetes (k3s)
デプロイ構成
今回は管理のしやすさを考慮し、フロントエンド(Open WebUI)とバックエンド(Ollama)を分離して構成しています。
- フロントエンド: k3s上にHelmを用いてデプロイ
helm repo add open-webui https://helm.openwebui.com/ helm repo update helm install open-webui open-webui/open-webui -f values.yaml -n webui
values.yamlは環境に合わせて適宜設定。
helm repo add open-webui https://helm.openwebui.com/
helm repo update
helm install open-webui open-webui/open-webui -f values.yaml -n webui
# values.yamlは環境に合わせて適宜設定。- バックエンド: Docker上でOllamaを実行 実運用を想定し、推論処理を行うBackendを分離させることで、デバッグやリソース調整をしやすくしています。
【注意】Ollamaのバージョンについて
LFM2.5-1.2B(GGUF版)を動かす際、古いバージョンのOllamaでは以下のエラーが発生することがあります。
Error: 500 Internal Server Error: llama runner process has terminated: error loading model: missing tensor ‘output_norm’
Error: 500 Internal Server Error: llama runner process has terminated: error loading model: missing tensor 'output_norm'この問題に対応するため、Ollamaは v0.13.4 以降を利用してください。 (参考:Hugging Face Discussion)
LFM2.5-1.2Bの準備
Open WebUIの管理者パネルから簡単にモデルを導入できます。
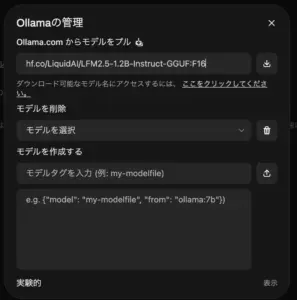
model download
- 右上の「管理者パネル」→「設定」→「接続」を開く。
- Ollamaのセクションにある「モデルをプル(Pull a model)」の入力欄に、Hugging FaceのモデルURLまたは識別子を入力してダウンロードします。
- モデルURL: LFM2.5-1.2B-Instruct-GGUF
ダウンロードした後はモデルを選択すれば、ChatGPTのように利用できます。
実行例と性能評価
1.2Bという極めて軽量なパラメータ数ながら、応答は非常に高速です。いくつかのパターンでテストを行いました。
1. プログラミング・構造化データ出力
問い: 「東京、ニューヨーク、ロンドンの3都市の情報を調査し、指定のJSONフォーマットで出力してください。」
結果: 余計な解説を挟まず、正確なJSONコードのみを返しました。API経由でシステムに組み込む際の信頼性が高いと感じます。
2. 情報抽出と要約
問い: 「打ち合わせメモから(1)決定事項、(2)宿題、(3)次回の予定をMarkdownの表形式で抽出してください。」
結果: 文脈を正確に把握し、綺麗な表形式で整理されました。
3. ステップバイステップの思考
問い: 「リモートワークのメリットを3つ挙げ、それらをデメリットに変換し、最後にハイブリッドワークのキャッチコピーを考えてください。」
結果: 論理の飛躍がなく、指示されたステップを忠実に実行できました。
4. 制約条件の遵守
問い: 「200文字以内、『便利』『最高』は禁止、ハッシュタグを付ける」という制約での紹介文作成。
**結果:**ネガティブチェック(禁止語句)もしっかり機能しており、実用レベルです。
まとめ
今回 LFM2.5-1.2B を触ってみて、特定の用途(データ整形や自動応答のパイプラインなど)においては、ChatGPTやGeminiのような巨大な汎用モデルよりも、こうした小型LLMの方が「速い・安い・セキュア」という三拍子が揃っており、使い勝手が良いと感じました。
特にプライバシーや機密情報を扱う業務では、自前環境で完結できるメリットは計り知れません。Open WebUIのRAG(基盤知識追加)や関数機能と組み合わせれば、さらに夢が広がります。
まずは手軽に試してみたいという方は、Liquid AI社が提供しているスマホアプリ「Apollo」でもこのモデルを体験できるので、ぜひチェックしてみてください。
参考リンク